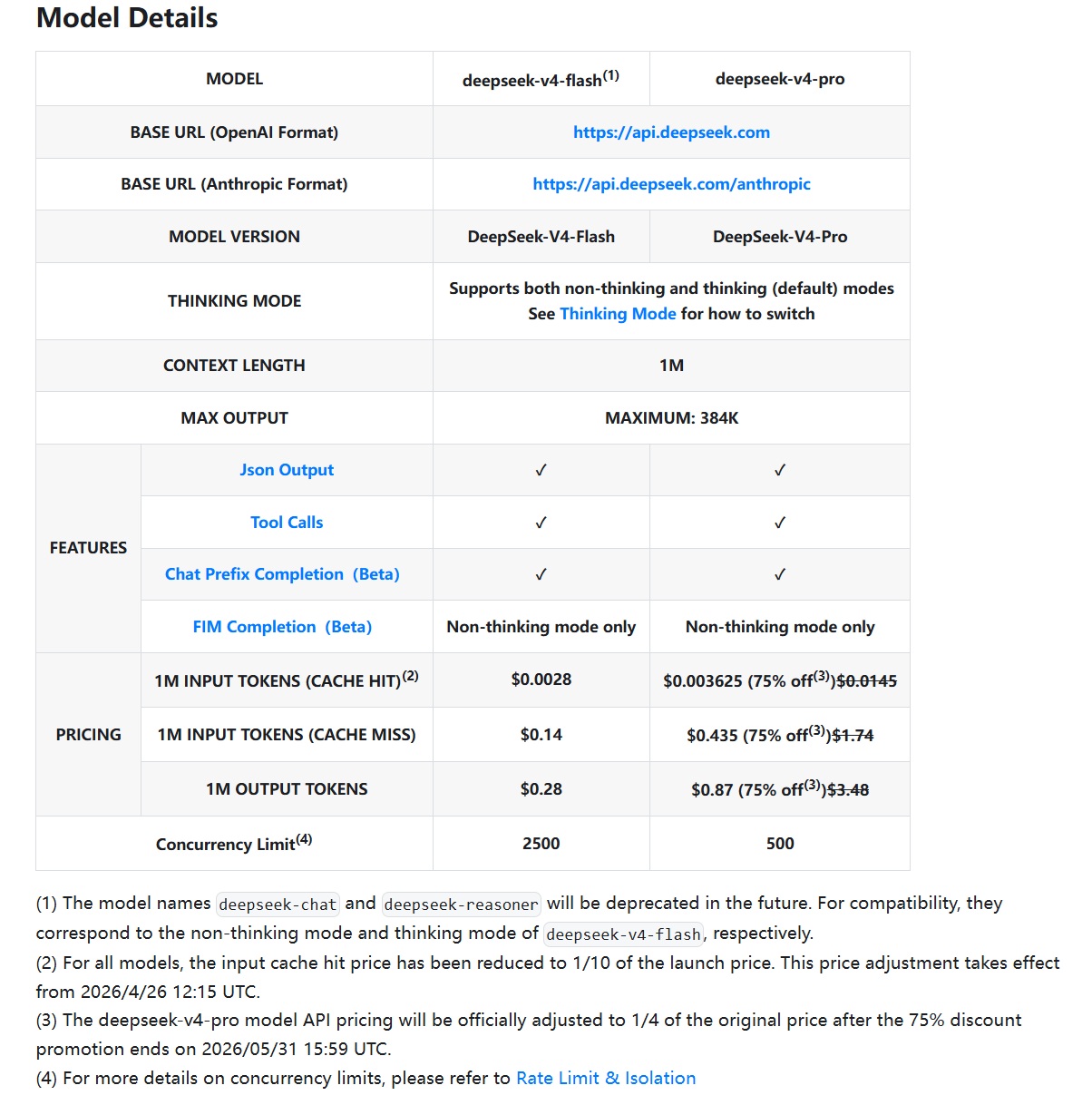
DeepSeek V4 Pro Review: My Nuclear-Powered AI Programming Assistant
DeepSeek V4 Pro Is the Cheapest Nuclear-Powered Donkey At first, the way I used AI was: Ask AI to write code I manually run the program, encounter problems Ask AI to write local logs and check the logs AI writes fix code again I run again AI checks logs again Repeat… Then I told DeepSeek V4 Pro: you must continuously fix and solve problems, automatically run the program after each fix, do automated testing, then check the run logs after closing the program, find problems in them, then fix again, run again, check logs again—until no more problems appear in the logs. ...